앙상블 기법(Ensemble Technique)
앙상블 기법은 무엇인가요? 앙상블 기법은 여러 개의 기본 모델을 결합하여 하나의 최적 예측 모델을 만드는 머신러닝 기법입니다. 앙상블 기법은 단일 모델보다 높은 예측 성능을 보일 수 있으며, 일반적으로 모델의 안정성과 성능을 향상시킵니다.
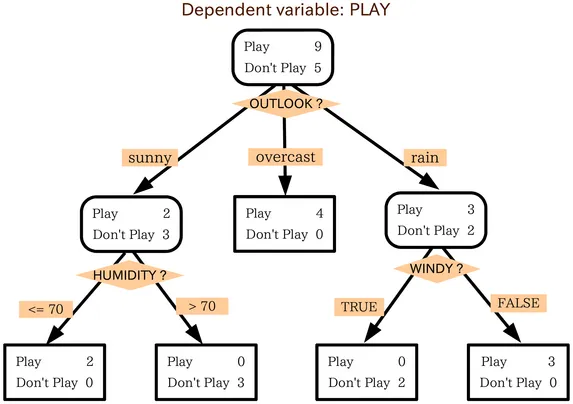
의사결정나무 (decision tree)는 조건에 기반하여 예측 값을 결정합니다. 예를 들어, 위의 의사결정나무 예시는 개인이 외출을 해야 할 지 여부를 결정합니다. 여러 날씨 요소를 고려하며 결정하거나 다른 질문으로 넘어갑니다. 여기서는 날씨가 흐릴 때마다 외출할 것입니다. 그러나 비가 오는경우엔, 바람이 불었는지 확인해야 합니다. 바람이 불면 외출하지 않을 것이고 바람이 불지 않는다면 외출 준비를 하면 됩니다.
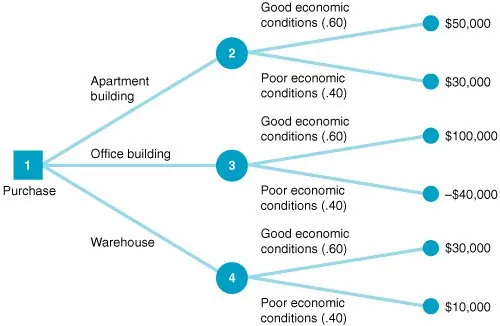
의사결정나무는 동일한 방식으로 위 유형의 문제도 해결할 수 있습니다. 왼쪽의 트리에서는 상업용 부동산에 투자해야 할지 결정합니다. 사무실 건물인지, 아파트 건물인지를 확인하고, 경제 상황과 투자 수익을 고려하여 결정 트리를 통해 문제를 해결할 수 있습니다.
의사결정나무를 만들 때 고려해야 할 여러 가지 요소가 있습니다. 어떤 사항이 기준인가? 각 질문의 분류 임계값은 무엇인가? 지속적으로 추가 질문을 추가함으로써 카테고리를 정의하고자 합니다. 앙상블 기법은 하나의 의사결정나무에만 의존하지 않고 의사결정나무의 샘플을 고려하여 각 분기점에서 사용할 기준 또는 질문을 계산하고, 샘플링된 의사결정나무의 집계 결과를 기반으로 최종 예측 값을 만들 수 있습니다
앙상블 기법은 크게 두 가지로 나눌 수 있습니다. (Bagging과 Boosting)

1. 평균화 기반 앙상블 기법 (Bagging): 여러 개의 예측 모델을 생성하고, 이들의 예측값을 평균하여 최종 예측값을 결정합니다. Bagging은 Bootstrap Aggregating의 줄임말로, 샘플을 중복 추출하여 각각의 모델을 학습시키고 이들의 예측 결과를 결합하는 방식입니다. 즉, 모델 간의 상관관계를 줄이기 위해 각각의 모델이 학습하는 데이터셋을 무작위로 구성하여 다양한 모델을 만들고, 이들의 예측 결과를 평균 또는 다수결 등으로 결합하는 방식입니다. Bagging은 오버피팅을 줄이고 예측의 안정성을 높이는 데 효과적입니다. 대표적인 알고리즘으로는 랜덤 포레스트가 있습니다.

랜덤 포레스트(Random Forest)
앙상블 학습(Ensemble Learning)의 일종으로, 여러 개의 결정 트리(Decision Tree)를 만들어 이들의 결과를 종합하여 예측을 수행하는 방식입니다.
랜덤 포레스트는 다음과 같은 과정으로 동작합니다.
- 데이터셋의 일부를 무작위로 선택하여 부트스트랩(Bootstrap) 샘플을 만듭니다. 이 부트스트랩 샘플은 중복을 허용하여 여러 번 선택될 수 있습니다.
- 각각의 부트스트랩 샘플을 사용하여 결정 트리를 만듭니다. 이 때, 각 노드에서 최적의 분할을 선택할 때, 전체 피처(feature) 중 일부만 사용하도록 무작위로 선택합니다. 이렇게 하면 결정 트리들이 서로 비교할 수 있는 다양한 모양을 갖게 되고, 과적합(Overfitting)을 줄일 수 있습니다.
- 각각의 결정 트리에서 나온 예측값들을 종합하여 최종 예측을 수행합니다. 이 때, 회귀(Regression) 문제의 경우는 평균값, 분류(Classification) 문제의 경우는 다수결로 예측값을 결정합니다.랜덤 포레스트는 결정 트리가 가진 장점인 해석력과 확장성을 그대로 유지하면서, 과적합 문제를 해결할 수 있습니다. 또한, 처리속도가 빠르고 다양한 데이터 타입에 대해 좋은 예측 성능을 보이기 때문에, 대부분의 문제에 적용할 수 있는 대표적인 머신러닝 알고리즘 중 하나입니다.
2. 부스팅 기반 앙상블 기법: 약한 학습기(Weak Learner)를 여러 개 결합하여 강한 학습기(Strong Learner)를 만드는 방법입니다. 약한 학습기는 일반적으로 과적합을 방지하기 위해 단순한 모델을 사용하며, 이를 결합하여 강한 모델을 만들어내는 방식으로 동작합니다. Boosting은 약한 예측 모델을 순차적으로 학습시켜 강력한 모델을 만드는 방식입니다. 이전 모델이 잘못 예측한 샘플에 가중치를 더 주어 다음 모델에서 더 많이 학습할 수 있도록 하는 방식입니다. 즉, 이전 모델의 오차를 보완하는 방식으로 진행되며, 각 모델은 이전 모델의 학습 결과를 기반으로 학습됩니다. Boosting은 예측의 정확도를 높이는 데 효과적입니다. 대표적인 알고리즘으로는 그래디언트 부스팅, XGBoost, LightGBM 등이 있습니다. 대표적인 부스팅 기반 앙상블 기법으로는 AdaBoost, Gradient Boosting, XGBoost, LightGBM 등이 있습니다.

Gradient Boosting
Boosting 알고리즘 중 하나로, 경사 하강법을 사용하여 약한 학습기(weak learner)를 이용해 강력한 예측 모델을 만드는 방법입니다. Gradient Boosting의 핵심 아이디어는, 이전 모델의 예측 결과와 실제 값의 차이(residual)에 대해 새로운 모델을 학습시켜 예측 결과를 보완하는 것입니다. 이 과정을 반복하여 예측 오류를 최소화하는 모델을 만들어내는 것이 목표입니다.
구체적인 과정을 살펴보면, Gradient Boosting은 다음과 같은 단계로 이루어집니다.
- 초기 모델 생성: Gradient Boosting은 일반적으로 결정 트리(Decision Tree) 모델을 약한 학습기로 사용합니다. 따라서 초기 모델은 단일 결정 트리로 구성됩니다.
- 오류 계산: 초기 모델을 통해 예측한 값과 실제 값 사이의 차이를 계산합니다. 이것을 예측 오류(prediction error)라고 합니다.
- 오류 보정: 예측 오류를 보정하기 위해 새로운 모델을 학습시킵니다. 이 때, 오류를 보정하는 방식으로는 경사 하강법(Gradient Descent)을 사용합니다. 경사 하강법은 오류를 최소화하는 방향으로 모델 파라미터를 업데이트합니다.
- 모델 결합: 새로운 모델을 초기 모델과 결합하여 오류 보정 효과를 누적시킵니다. 이 과정을 반복하여 여러 개의 모델을 결합하여 강력한 예측 모델을 만듭니다.
Gradient Boosting은 다양한 하이퍼파라미터를 조정하여 성능을 향상시킬 수 있습니다. 대표적인 Gradient Boosting 알고리즘으로는 XGBoost, LightGBM 등이 있습니다.
앙상블 기법은 데이터셋에 따라 예측 성능이 달라질 수 있습니다. 따라서, 여러 앙상블 기법을 시도해보고 최적의 방법을 찾는 것이 중요합니다.
'머신러닝' 카테고리의 다른 글
| 나이브 베이즈 (naïve bayes) (0) | 2023.03.28 |
|---|---|
| 파이썬 라이브러리를 활용한 머신러닝 (1/3) (3) | 2023.03.24 |
| 정규화 (Normalization) (0) | 2023.03.21 |
| 과대적합(Overfitting)과 과소적합(Underfitting) (0) | 2023.03.20 |
| 머신러닝의 분류 (taxonomy of Machine learning) (0) | 2023.03.16 |