만약 데이터셋에 수백 개의 특성 또는 데이터 포인트가 있고 이를 2차원 또는 3차원 공간에 나타내고 싶다면 어떻게 해야 할까요? T-SNE는 "t-distributed stochastic neighbor embedding"의 약자로, 고차원 데이터를 시각화하기 위한 비선형 차원 축소 기법입니다.

T-SNE는 주어진 데이터셋에서 각 데이터 포인트의 유사도를 계산하여, 이를 새로운 공간상에서 가까운 거리에 위치하도록 매핑하는 것을 목표로 합니다. 이를 위해, T-SNE는 먼저 각 데이터 포인트에서 가까운 이웃을 찾고, 그 이웃들 간의 유사도를 계산합니다. 이후, 각 데이터 포인트는 이웃들과의 유사도를 고려하여 새로운 공간상의 좌표를 계산합니다.
T-SNE는 비선형 차원 축소 기법으로, 고차원 데이터의 복잡한 구조와 패턴을 보존할 수 있습니다. 이를 통해, T-SNE는 고차원 데이터의 시각화를 용이하게 할 뿐만 아니라, 데이터 간의 관계나 패턴을 쉽게 파악할 수 있도록 도와줍니다.
데이터셋의 차원을 축소하면서도 데이터셋에서 가장 많은 정보를 보존하는 두 가지 일반적인 기술은 주성분 분석(PCA)과 t-분포 확률적 이웃 임베딩(t-SNE)입니다. 이 둘의 특성에 대해 체크해 보겠습니다.
차원축소 관점에서 PCA와 t-SNE의 비교
데이터 차원 축소의 목표
- 고차원 데이터에서 중요한 구조 또는 정보를 가능한 한 많이 남기는 것
- 낮은 차원의 표현에서 데이터의 해석 가능성을 높이는 것
- 차원 축소로 인한 데이터 정보 손실을 최소화하는 것
PCA와 t-SNE는 모두 비지도 학습 차원 축소 기술이며, 고차원 데이터를 낮은 차원 공간에 시각화하기 위해 사용됩니다. PCA는 데이터를 가장 큰 분산으로 변환하는 선형 차원 축소 기술입니다. 즉, 고차원 데이터를 적은 수의 주요 주성분으로 압축합니다. 이는 데이터 포인트 들 간 거리와 방향을 보존하지만, 비선형 구조를 보존하지는 못합니다.
반면, t-SNE는 비선형 차원 축소 기술로, 고차원 데이터의 구조와 패턴을 보존하면서 낮은 차원으로 임베딩합니다. 이는 데이터 포인트들 간의 국부적인 구조를 보존하므로 고차원 공간에서 멀리 떨어져 있는 포인트들은 낮은 차원에서 더 멀어질 수 있습니다. 따라서 PCA는 선형적인 구조를 강조하며 비교적 단순하고 빠른 계산을 제공합니다. 반면, t-SNE는 비선형 구조와 국부적인 구조를 보존하며 데이터셋이 복잡할 경우 유용합니다.
주성분 분석(PCA)
- 비지도 형태로 사용되는 결정론적 알고리즘으로, 특징 추출 및 시각화에 사용됩니다.
- 저차원 공간에서 유사하지 않은 포인트들이 멀리 떨어지도록 하는 선형 차원 축소 기술을 적용합니다.
- 고유값을 사용하여 데이터의 분산을 보존하면서 원래 데이터를 새로운 데이터로 변환합니다.
- 아웃라이어 데이터는 PCA에 영향을 미칩니다.
t-분포 확률적 이웃 임베딩(t-SNE)
- 비지도 형태로 사용되는 확률적 알고리즘으로, 시각화에만 사용됩니다.
- 저차원 공간에서 매우 유사한 데이터 포인트들이 가깝게 유지되도록 하는 비선형 차원 축소 기술을 적용합니다.
- student t-분포를 사용하여 낮은 차원 공간에서 두 포인트 간의 유사도를 계산하여 데이터의 국부 구조를 보존합니다.
- t-SNE는 가우시안 분포 대신 꼬리가 무거운 학생 t-분포를 사용하여 저차원 공간에서 두 포인트 간의 유사도를 계산하므로, 혼잡성과 최적화 문제를 해결하는 데 도움이 됩니다. 아웃라이어 데이터는 t-SNE에 영향을 미치지 않습니다.
t-SNE는 Laurens van der Maaten와 Geoffrey Hinton이 개발한 시각화를 위한 비지도 기계 학습 알고리즘입니다.t-SNE는 다음과 같은 단계로 작동합니다.
Step 1: 고차원 공간에서 근접한 데이터 포인트들 간의 쌍별 유사도를 찾습니다.
t-SNE는 데이터 포인트 xᵢ와 xⱼ 사이의 고차원 유클리드 거리를 조건부 확률 P(j|i)로 변환합니다.
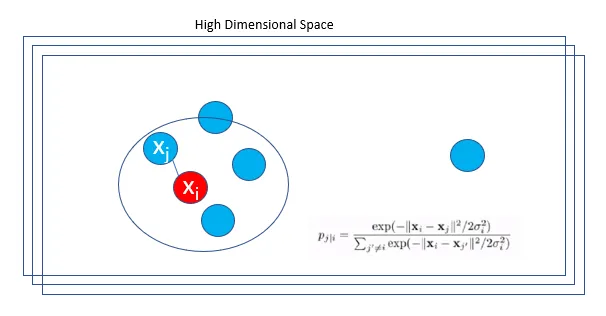
xᵢ는 xᵢ를 중심으로 한 가우시안 분포의 확률 밀도 비례에 따라 xⱼ를 이웃으로 선택합니다. σᵢ는 데이터 포인트 xᵢ를 중심으로 하는 가우시안의 분산입니다. 두 데이터 포인트의 확률 밀도는 유사성에 비례합니다. 인접한 데이터 포인트의 경우, p(j|i)는 상대적으로 높고, 멀리 떨어진 점의 경우, p(j|i)는 거의 없을 것입니다. 고차원 공간에서 조건부 확률을 대칭적으로 만들어 최종 유사성을 얻습니다.
대칭적인 조건부 확률은 아래와 같이 두 확률을 평균하여 얻습니다.

Step 2: 고차원 공간에서 데이터 포인트를 저차원 맵으로 매핑합니다. yᵢ와 yⱼ는 고차원 데이터 포인트 xᵢ와 xⱼ의 저차원 상대편입니다.

점 yᵢ를 중심으로 한 가우시안 분포 아래에 있는 P(j|i)와 유사한 조건부 확률 q(j|i)를 계산하고, 그런 다음 확률을 대칭화합니다.
3단계: Kullback-Leibler divergence(KL divergence)를 기반으로 한 gradient descent를 사용하여 Pᵢⱼ와 qᵢⱼ 간의 불일치를 최소화하는 저차원 데이터 표현을 찾습니다.

t-SNE는 gradient descent를 사용하여 저차원 공간에서 데이터 포인트를 최적화합니다.
Step 4: 저차원 공간에서 두 점 사이의 유사성을 계산하기 위해 Student-t 분포를 사용합니다.
t-SNE는 가우시안 분포가 아닌 하나의 자유도를 갖는 heavy-tailed Student-t 분포를 사용하여 저차원 공간에서 두 점 사이의 유사성을 계산합니다. T-분포는 낮은 차원 공간에서 포인트의 확률 분포를 생성하며, 이는 과적합 문제를 해결하는 데 도움이 됩니다.
데이터셋에 t-SNE 적용 방법
Python에서 코드를 작성하기 전에 t-SNE에 사용할 수 있는 몇 가지 중요한 매개 변수를 이해해야 합니다.
- n_components: 중첩된 공간의 차원입니다. 이것은 고차원 데이터가 변환될 저차원으로, 2차원 공간의 기본값은 2입니다.
- Perplexity: Perplexity는 t-SNE 알고리즘에서 사용되는 최근접 이웃의 수와 관련이 있습니다. 더 큰 데이터셋은 일반적으로 더 큰 perplexity를 필요로 합니다. Perplexity는 5에서 50 사이의 값을 가질 수 있으며, 기본값은 30입니다.
- n_iter: 최적화를 위한 최대 반복 횟수입니다. 적어도 250이 되어야 하며, 기본값은 1000입니다.
- learning_rate: t-SNE의 학습률은 일반적으로 [10.0, 1000.0] 범위 내에 있으며, 기본값은 200.0입니다.
TSNE-FashionMNIST 데이터

MNIST 데이터를 가지고 PCA와 t-SNE를 적용해서 10개의 그룹으로 나누어 보겠습니다.
PCA결과

t-SNE결과 (n_iter=300, perplexity=40)

t-SNE결과 (n_iter=1500, perplexity=40)

반복횟수가 많아지니 구분이 더욱 확실한 느낌입니다.
아래는 t-SNE의 원 개발자의 깃헙입니다. 자세히 알고 싶으시다면 아래를 방문하여 주시기 바랍니다
https://lvdmaaten.github.io/tsne/
t-SNE
t-SNE
lvdmaaten.github.io
'머신러닝' 카테고리의 다른 글
| 그리드 서치 (Grid Search) (0) | 2023.03.28 |
|---|---|
| 교차 검증(Cross-validation) (0) | 2023.03.28 |
| 비음수 행렬분해(Non-negative Matrix Factorization, NMF) (0) | 2023.03.28 |
| 서포트 벡터 머신(Support Vector Machine) (0) | 2023.03.28 |
| 나이브 베이즈 (naïve bayes) (0) | 2023.03.28 |