주성분 분석(Principal Component Analysis, PCA)은 머신러닝에서 차원 축소에 사용되는 비지도학습 알고리즘입니다. 상관관계가 있는 여러 특성들의 관측치를 직교 변환을 통해 선형적으로 상관성이 없는 주성분으로 변환하고 이러한 변환된 새로운 특성들은 주성분이라고 부릅니다. 주성분 분석은 탐색적 데이터 분석과 예측 모델링에 많이 사용되며 데이터셋의 분산을 줄이기 위해 강력한 패턴을 도출하는 방법입니다. 아래와 같은 3차원 데이터 셋을 가정하는 겁니다. 3개의 축을 기준으로 각 데이터의 위치를 설명해야 합니다.
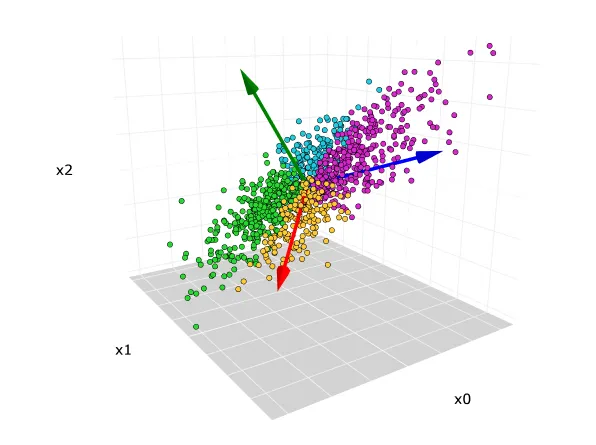
PCA는 일반적으로 고차원 데이터를 투영할 저차원 면을 찾는데, 이는 각 특성의 분산을 고려하여 작동합니다. 분산이 높을수록 좋은 분류가 가능하므로 데이터 차원을 축소시킵니다. PCA의 실제 적용 분야로는 이미지 처리, 영화 추천 시스템, 다양한 통신 채널에서의 전력 할당 최적화 등이 있으며, 이는 특성 추출 기술로서 중요한 변수는 유지하고 덜 중요한 변수는 제거합니다. 3차원으로 설명해야 할 데이터를 2차원으로 내렸습니다. 즉, 각 데이터의 위치표시를 2개의 핵심적인 차원으로 차원축소가 일어난 것입니다.
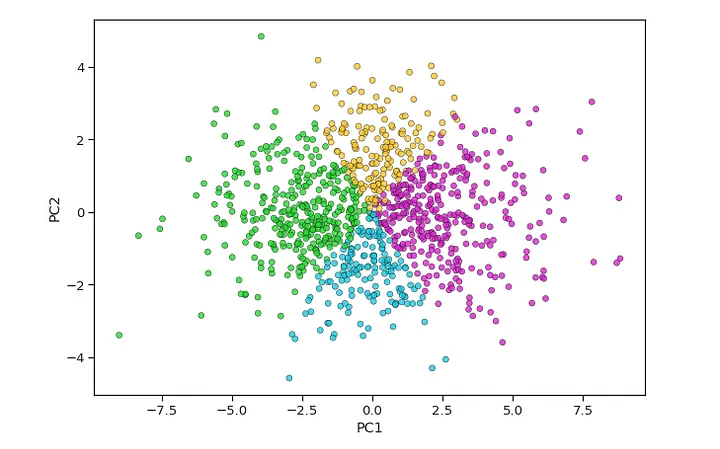
PCA의 주요 성분
PCA의 변환된 새로운 특성 또는 출력은 주성분(Principal Components)이라고 합니다. 이러한 주성분의 수는 데이터셋에 있는 원래 특성의 수와 같거나 적을 수 있습니다. 이러한 주성분의 몇 가지 특징은 다음과 같습니다.
- 주성분은 원래 특성들의 선형 결합이어야 합니다.
- 이러한 성분은 직교하며, 즉, 두 변수 간의 상관 관계가 0입니다.
- 각 성분의 중요도는 1에서 n까지 갈수록 감소합니다. 즉, 1번 성분이 가장 중요하고, n번 성분이 가장 적은 중요도를 가집니다.
PCA 알고리즘의 단계
- 데이터셋 구하기
우선 입력 데이터셋을 가져와서 훈련 세트와 검증 세트로 나누어야 합니다. - 데이터 구조로 표현하기
데이터셋을 데이터 프레임화 해야 합니다. 여기서 각 행은 데이터 항목에 해당하고, 각 열은 특징에 해당합니다. 열의 수는 데이터셋의 차원입니다. - 데이터 표준화하기
데이터셋을 표준화하는데 특정 열에서 분산이 높은 특성은 분산이 낮은 특성보다 더욱 중요합니다. 특성의 중요성과 특성의 분산과 독립적인 경우, 각 열의 데이터 항목을 해당 열의 표준 편차로 나눕니다. 여기서 행렬을 Z라고 부릅니다. - Z의 공분산 계산하기
Z의 공분산을 계산하기 위해 Z 행렬을 전치하고, 전치한 행렬을 Z와 곱합니다. 이는 Z의 공분산 행렬입니다. - 고유값과 고유 벡터 계산하기
이제 결과 공분산 행렬 Z의 고유값과 고유 벡터를 계산해야 합니다. 공분산 행렬의 고유 벡터는 정보가 높은 축의 방향입니다. 이러한 고유 벡터의 계수는 고유값으로 정의됩니다. - 고유벡터 정렬
이 단계에서는 모든 고유값을 가져와 내림차순으로 정렬하고, 동시에 고유벡터를 해당하는 고유값으로 정렬하여 고유값 행렬 P를 생성합니다. - 새로운 특징 또는 주성분 계산
여기에서 우리는 새로운 특징을 계산합니다. 이를 위해 P 행렬을 Z에 곱합니다. 결과 행렬 Z에서 각 관측값은 원래 특징의 선형 조합입니다. Z 행렬의 각 열은 서로 독립적입니다. - 새로운 데이터셋에서 중요하지 않거나 덜 중요한 특징 제거
새로운 특징 집합이 발생했으므로, 여기에서 어떤 것을 유지하고 어떤 것을 제거할지 결정합니다. 이는 새로운 데이터셋에서 관련성이나 중요성이 적은 특징을 제거하고, 중요한 특징만 유지하는 것을 의미합니다.