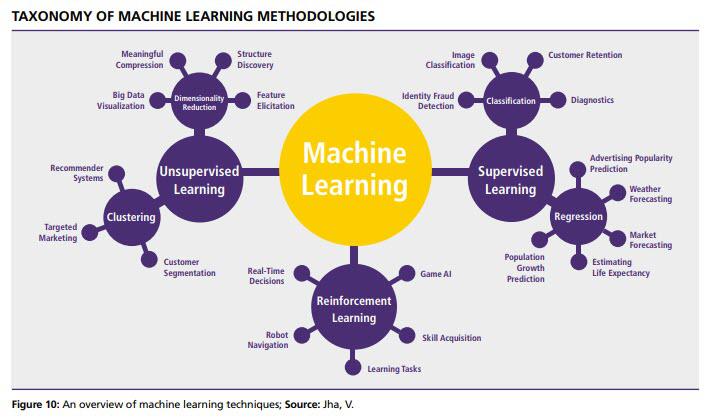
머신러닝의 흐름을 이해할 수 있도록 분류체계에 대한 이해를 돕고자 한다.
서플라이체인과 관련하여 머신러닝이 사용된다는 포브스의 기사가 있고 관련 사진을 공유한다. 시간이 되시는 분들은 출처링크에 가서 기사를 읽어보는 것을 추천한다.
Forbes - 10 Ways Machine Learning Is Revolutionizing Supply Chain Management
머신러닝의 3가지 분류
지도학습(Supervised Learning) - 분류 , 회귀
- 정답을 알려주며 학습시키는 것을 의미한다.
- 환자별 질병 증상데이터에(input) 발병 미발병 등 (labelling)을 기록하여 컴퓨터에 전달한다.
- 컴퓨터는 학습과 검증데이터를 통해(train set, test set) 학습이 올바로 되었는지 확인할 수 있다.
- 지도학습에는 크게 판독을 위한 분류(classification)와 결과 예측을 위한 회귀(regression)가 있다.
분류(classification): 이 사진은 자동차인가 오토바이인가? 이 제품은 제대로 조립되었는가?
회귀(regression): 월소득이 2000불 늘어나고 여유시간이 2시간 늘었을 때 여가생활에 얼마를 더 지출할 것인가?
비지도학습(Unsupervised Learning) - 군집화, 차원축소
- 컴퓨터에 정답을 따로 알려주지 않는다. (label이 없다) 데이터의 특성을 파악하여 그루핑한다.
- 정답이 없이 학습을 통해 결론이 나야하므로 지도학습 대비 많은량의 데이터가 필요하다.
- 비지도학습의 대표적인 방법으로 클러스터링(Clustering), 주성분분석(Principal Component Analysis) 이 있다.
강화학습(Reinforcement Learning) - 게임산업, 실시간결정, 로봇네비게이션
자신이 한 행동에 대해 보상(reward)을 받으며 학습하는 것을 의미한다. (딱 들었을 때 게임이 생각남)
아래는 강화학습의 구성요소이다.
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임의 규칙을 따로 입력하지 않고 상태(state)와 환경(environment)에서 에이전트(Agent)가 보상(reward)를 얻기위해 행동(action)한다. 학습을 진행하며 점점 많은 보상(reward)를 획득할 수 있는 전략을 확립한다.
모든 상황에 대해 어떤 행동을 해야 하는지 답을 설정하려고 드는 것은 불가능하기 때문에 지도 학습(Supervised Learning)의 분류(Classification)를 통해서는 이를 달성할 수 없다. 이러한 문제를 해결하고자 나온 것이 강화학습이다.
자율주행, 게임 AI 등에 사용되고 있으며 딥마인드의 알파고는 너무나 유명한 예시이다.
Markov Decision Process (MDP)에서 이러한 개념에 대해 자세히 배울 수 있다. (필자의 기말고사 문제 중 하나였음)

게임 AI관련 관심있는 분들은 open AI의 Gymnasium 라이브러리를 사용해보는 것을 추천한다.
코드예제도 있고 사이트를 방문하여 더욱 자세한 설명을 확인할 수 있다. 기존 GYM 라이브러리와 호환되며 API도 제공된다.
스크린 상의 코드를 입력해 보자. 아래와 같은 결과물을 얻을 수 있다.


아래의 도표는 머신러닝 알고리즘 사용 시 많이 사용되는 싸이킷 런 (scikit-learn) 공식사이트의 머신러닝 유형 별 방법론 적용 분류도이다. 데이터의 목적과 특성에 따라 알맞는 방법론 적용에 대한 기준과 체계를 확인할 수 있다.

'머신러닝' 카테고리의 다른 글
| 나이브 베이즈 (naïve bayes) (0) | 2023.03.28 |
|---|---|
| 파이썬 라이브러리를 활용한 머신러닝 (1/3) (3) | 2023.03.24 |
| 앙상블 기법(Ensemble Technique) (0) | 2023.03.23 |
| 정규화 (Normalization) (0) | 2023.03.21 |
| 과대적합(Overfitting)과 과소적합(Underfitting) (0) | 2023.03.20 |