로지스틱 회귀(Logistic Regression)는 분류(Classification) 알고리즘 중 하나로, 입력 변수(x)와 이진 종속 변수(y) 사이의 관계를 찾는 모델입니다. 이진 종속 변수는 보통 0과 1로 표현되며, 로지스틱 회귀 모델은 입력 변수와 이진 종속 변수 간의 선형 관계를 모델링하기 때문에 선형 분류 문제에 많이 사용됩니다.
로지스틱 회귀 모델은 이진 분류뿐만 아니라 다중 분류(Multiclass Classification) 문제에도 적용할 수 있습니다. 다중 분류 문제에서는 소프트맥스 함수(Softmax function)를 사용하여 각 클래스에 대한 확률값을 계산하고, 가장 높은 확률값을 가진 클래스로 분류합니다.
로지스틱 회귀에서는 회귀선을 맞추는 대신 "S"자 모양의 로지스틱 함수를 적합시켜 최대값이 0 또는 1인 두 개의 값을 예측합니다. 로지스틱 함수의 곡선은 세포가 암인지 아닌지, 쥐의 체중에 따라 비만인지 아닌지 등과 같은 확률을 나타냅니다. 로지스틱 회귀는 연속 및 이산 데이터셋을 사용하여 새로운 데이터를 확률적으로 분류할 수 있으며 가장 효과적인 변수를 결정하는 것이 용이하기 때문에 중요한 기계 학습 알고리즘입니다. 아래 이미지는 로지스틱 함수를 보여줍니다.
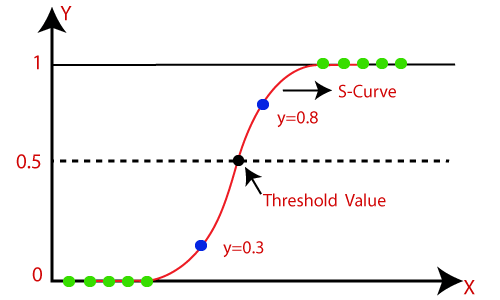
로지스틱 함수 (시그모이드 함수):
- 예측된 값을 확률로 매핑하는 데 사용되는 수학 함수입니다. 어떤 실수 값을 0과 1 사이의 값으로 매핑합니다.
- 로지스틱 회귀의 값은 0과 1 사이여야 하며, 이 한계를 넘어갈 수 없으므로 "S" 형태의 곡선을 형성합니다. 이 S-형태의 곡선을 시그모이드 함수 또는 로지스틱 함수라고 합니다.
- 로지스틱 회귀에서는 임계값(threshold value) 개념을 사용하여 0 또는 1의 확률을 정의합니다. 임계값 이상의 값은 1에 가깝고, 임계값 이하의 값은 0에 가깝습니다.
로지스틱 회귀의 가정:
- 종속 변수는 범주형이어야 합니다.
- 독립 변수는 다중공선성을 가지면 안 됩니다.
로지스틱 회귀의 한계:
로지스틱 회귀 모델은 선형 회귀 모델과 유사하지만, 종속 변수가 이진 변수이기 때문에 종속 변수의 값을 0과 1 사이의 확률값으로 변환하는 시그모이드 함수(Sigmoid function)를 사용합니다. 이러한 변환이 가능한 이유는 시그모이드 함수의 출력값이 항상 0과 1 사이이기 때문입니다. 로지스틱 회귀 모델에서는 이러한 시그모이드 함수를 사용하여 입력 변수와 종속 변수 사이의 관계를 모델링하고, 최적화 알고리즘을 사용하여 모델 파라미터를 학습합니다.
로지스틱 회귀 모델은 간단하고 이해하기 쉽다는 장점이 있으며, 새로운 데이터에 대한 예측이 빠르고 정확합니다. 또한, 과적합(Overfitting)을 방지하기 위해 규제(Regularization)를 적용할 수 있습니다. 하지만, 입력 변수와 종속 변수 간의 관계가 선형적이어야 한다는 가정이 있기 때문에, 비선형적인 데이터 분류 문제에는 적용하기 어렵습니다.
'확률통계 > 회귀분석' 카테고리의 다른 글
| 정규화 (Regularization) (0) | 2023.03.20 |
|---|---|
| 선형회귀(Linear Regression) (0) | 2023.03.20 |