TF-IDF(Term Frequency-Inverse Document Frequency)는 자연어 처리에서 사용되는 통계적인 방법 중 하나입니다. 문서의 중요한 단어를 파악하는 데 사용됩니다. TF-IDF는 각 단어의 가중치를 계산하여 문서의 중요도를 평가합니다. 이 방법은 각 단어의 등장 횟수(TF)와 문서 집합에서 해당 단어가 등장한 문서의 수(Inverse Document Frequency, IDF)를 고려합니다.
각 단어의 등장 횟수(TF)는 단어가 문서 내에서 얼마나 자주 등장하는지를 나타냅니다. 반면에, 단어가 전체 문서 집합에서 얼마나 희귀한지를 측정하는 IDF는 특정 단어가 다른 문서에서도 자주 등장할수록 그 단어에 대한 가중치가 낮아집니다. 즉, TF-IDF는 단어의 빈도수와 전체 문서 집합에서의 등장 빈도수를 고려하여, 문서 내에서 어떤 단어가 중요한 단어인지를 판단하는 방법입니다. 이를 이용하여 문서 검색, 문서 분류 등의 분야에서 효과적으로 활용됩니다.
구성요소 별 설명
단어 빈도(Term Frequency, tf)는 말뭉치(corpus)의 각 문서에서 해당 단어가 나타난 빈도를 나타내는 값입니다. 해당 문서에서 해당 단어가 나타난 횟수를 해당 문서의 총 단어 수로 나눈 비율입니다. 문서 내에서 해당 단어가 더 많이 나타날수록 해당 값은 증가합니다. 각 문서마다 고유한 tf 값을 가지고 있습니다.

역문서 빈도 (idf) : 말뭉치(corpus) 내 모든 문서에서 드물게 등장하는 단어의 가중치를 계산하는 데 사용됩니다. 말뭉치 내에서 드물게 나타나는 단어는 높은 IDF 점수를 가지게 됩니다. 아래의 수식으로 표현됩니다.

df(t) = N(t)
where
df(t) = Document frequency of a term t
N(t) = Number of documents containing the term t
단어 빈도는 단일 문서 내에서 해당 단어의 출현 빈도를 나타내며, 문서 빈도는 해당 단어가 포함된 전체 문서 집합 N에서의 등장 횟수를 나타냅니다. 이는 전체 말뭉치에 따라 달라지기 때문에 단일 문서에서의 단어 빈도와 다릅니다. 이제 역문서 빈도의 정의를 살펴보겠습니다. 단어의 IDF는 말뭉치 내에서 해당 텍스트의 빈도로 분리된 문서 수입니다.
이 두 가지를 결합하여, 우리는 코퍼스 내 문서에서 단어의 TF-IDF 점수 (w)를 도출할 수 있습니다. 이는 TF와 IDF의 곱으로 표현됩니다:
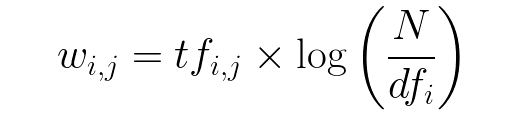

사용예시
문장 1 : The car is driven on the road.
문장 2: The truck is driven on the highway.
위 두 문장을 대상으로 TF-IDF를 계산해보겠습니다.

위의 표에서 일반적인 단어들의 TF-IDF 값은 0인 것을 알 수 있습니다. 이는 그들이 중요하지 않다는 것을 보여줍니다. 반면에, "car", "truck", "road", "highway"의 TF-IDF 값은 0이 아닙니다. 이러한 단어들은 더 중요합니다.
위키백과 내용을 참고하시기 바랍니다. 설명을 참조하여 주시기 바랍니다.
'머신러닝' 카테고리의 다른 글
| 희소행렬 (sparse matrix) (0) | 2023.03.29 |
|---|---|
| 혼동 행렬 (Confusion matrix) (0) | 2023.03.29 |
| 그리드 서치 (Grid Search) (0) | 2023.03.28 |
| 교차 검증(Cross-validation) (0) | 2023.03.28 |
| T-SNE (t-distributed stochastic neighbor embedding) (0) | 2023.03.28 |