
Confusion matrix(혼동 행렬)는 분류 모델의 예측 결과를 평가하는 데 사용되는 표입니다. 이는 정확도(accuracy) 외에도 모델의 성능을 다양한 측면에서 평가할 수 있도록 도와줍니다.
혼동 행렬은 일반적으로 이진 분류(binary classification)에 대해 설명됩니다. 이 경우, 분류 모델은 두 개의 클래스 중 하나에 속하는 샘플을 예측하려고 합니다. 예를 들어, 암 진단 분류 모델은 종양이 악성(malignant)인지 양성(benign)인지 예측하려고 할 수 있습니다.
이진 분류의 혼동 행렬은 다음과 같이 4개의 항목으로 구성됩니다.
- True Positive (TP): 실제 클래스가 양성이고, 모델이 양성으로 예측한 샘플 수
- False Positive (FP): 실제 클래스가 음성이지만, 모델이 양성으로 예측한 샘플 수
- False Negative (FN): 실제 클래스가 양성이지만, 모델이 음성으로 예측한 샘플 수
- True Negative (TN): 실제 클래스가 음성이고, 모델이 음성으로 예측한 샘플 수
이러한 항목은 다음과 같이 표로 나타낼 수 있습니다.
| Predicted Positive | Predicted Negative | |
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
각각의 항목은 모델의 예측 결과와 실제 레이블의 일치 여부에 따라 분류됩니다. 이를 바탕으로 다양한 성능 지표를 계산할 수 있으며, 이러한 지표를 통해 모델의 예측력을 평가할 수 있습니다. 아래 예시를 통하여 자세히 설명하고자 합니다.
산출 예시
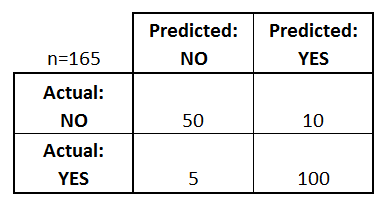
두 개의 가능한 예측 클래스(predicted), "예"와 "아니오"가 있습니다. 질병의 존재를 예측하는 경우 "예"는 질병이 있음을 의미하고, "아니오"는 질병이 없음을 의미합니다. 총 165명의 환자가 해당 질병의 존재 여부를 검사 받았습니다.
165개의 케이스 중, 혼동행렬은 "예"를 110번, "아니오"를 55번 예측했습니다. (predicted). 실제로, 샘플에서 105명의 환자가 질병을 가지고 있으며, 60명의 환자는 질병이 없습니다. 이제 가장 기본적인 용어를 정의해 봅시다. 이 용어들은 전체 숫자(비율이 아님)입니다.
예시를 기반으로 각 행렬의 의미를 확인해 보겠습니다.
- True positives (TP): 질병이 있다고 예측하고, 실제로 질병이 있는 경우입니다.
- True negatives (TN): 질병이 없다고 예측하고, 실제로 질병이 없는 경우입니다.
- False positives (FP): 질병이 있다고 예측했지만, 실제로는 질병이 없는 경우입니다. ("type 1 error" 라고도 함)
- False negatives (FN): 질병이 없다고 예측했지만, 실제로는 질병이 있는 경우입니다. ("type 2 error" 라고도 함)

계산용어 설명:
- 정확도 (Accuracy): 분류기가 전체적으로 얼마나 올바른지를 나타냅니다.
(TP + TN) / 총 개수 = (100+50) / 165 = 0.91
- 틀린 비율 (Misclassification Rate): 전체적으로 얼마나 자주 틀리는지를 나타냅니다.
(FP + FN) / 총 개수 = (10+5) / 165 = 0.09
1에서 정확도를 빼면 됩니다. "오류율"이라고도 합니다.
- True Positive Rate (TPR): 실제로 yes인 경우에 얼마나 자주 yes를 예측하는지를 나타냅니다.
TP / actual "yes" = 100/105 = 0.95
"Sensitivity" 또는 "Recall"로도 알려져 있습니다.
- False Positive Rate (FPR): 실제로 no인 경우에 얼마나 자주 yes를 예측하는지를 나타냅니다.
FP / actual "no" = 10/60 = 0.17
- True Negative Rate (TNR): 실제로 no인 경우에 얼마나 자주 no를 예측하는지를 나타냅니다.
TN / actual "no" = 50/60 = 0.83
1에서 False Positive Rate를 빼면 됩니다. "Specificity"로도 알려져 있습니다.
- 정밀도 (Precision): yes를 예측했을 때, 얼마나 자주 올바른지를 나타냅니다.
TP / predicted "yes" = 100/110 = 0.91
- 유병률 (Prevalence): 우리 샘플에서 yes 상태가 실제로 얼마나 자주 발생하는지를 나타냅니다.
actual "yes" / 총 개수 = 105/165 = 0.64
- 재현율(Recall)은 실제값이 Positive인 샘플 중에서 모델이 Positive로 예측한 비율입니다. 즉, 모델이 실제 Positive인 데이터를 얼마나 잘 잡아냈는지를 나타냅니다.
재현율 = TP / (TP + FN)
재현율이 높을수록 모델이 Positive인 경우를 놓치지 않고 잘 예측하는 것입니다. 하지만 재현율이 높으면 FP가 증가할 수 있으므로 모델의 성능을 평가할 때는 정밀도(Precision)와 함께 고려해야 합니다.
추가설명
FP 감소 & FN 증가 »> 정밀도 증가
FP 증가 & FN 감소 »> 재현율 증가
정밀도와 재현율은 분류 모델의 성능을 평가하기 위한 지표 중 두 가지입니다. 정밀도가 높으면 거짓을 잘 구분해내지만 참을 놓칠 수 있고, 재현율이 높으면 거짓을 잘 구분하지 못하지만 참을 놓치지 않습니다.
두 지표는 서로 트레이드 오프 관계에 있으며, 상황에 따라 어느 하나가 더 중요할 수 있습니다. 예를 들어, 암환자를 구별할 때는 재현율을 높이는 것이 좋습니다. 반면에, 판사가 재판을 할 때는 정밀도를 높이는 것이 좋습니다.
따라서, 모델의 목적과 상황에 맞게 정밀도와 재현율을 적절하게 조절하여 모델의 성능을 평가하고 개선할 수 있습니다.
기타 확인사항
- Null Error Rate: 항상 다수의 클래스를 예측할 때 얼마나 자주 잘못 예측하는지를 나타냅니다. (우리 예제에서 Null Error Rate는 60/165 = 0.36이 됩니다. 왜냐하면 항상 "예"를 예측한다면 60 개의 "아니오" 케이스에서만 잘못 예측할 것이기 때문입니다.) 이것은 분류기의 성능을 비교하기 위한 유용한 기준 지표가 될 수 있습니다. 그러나 특정 응용 프로그램에 대해 최상의 분류기는 때로는 Null Error Rate보다 높은 오류율을 갖을 수 있으며, 이것은 정확도 역설로 설명됩니다.
- Cohen's Kappa: 이것은 분류기가 우연히 수행할 것보다 얼마나 잘 수행되었는지를 측정하는 것입니다. 다른 말로하면, 모델의 Kappa 점수가 높으면 정확도와 Null Error Rate 사이에 큰 차이가 있습니다. (Cohen's Kappa에 대한 자세한 내용은 링크를 참조하세요.)
- F Score: 이것은 true positive rate(재현율)과 precision의 가중 평균입니다. (F Score에 대한 자세한 내용은 링크를 참조하세요.)
- ROC Curve: 이것은 모든 가능한 임계값에서 분류기의 성능을 요약하는 일반적으로 사용되는 그래프입니다. True Positive Rate(y 축)와 False Positive Rate(x 축)를 임계값을 변화시키면서 주어진 클래스에 대한 관측치를 할당할 때 생성됩니다. (ROC Curve에 대한 자세한 내용은 링크를 참조하세요.)
관련 라이브러리 설명 in scikit-learn
https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
Confusion matrix
Example of confusion matrix usage to evaluate the quality of the output of a classifier on the iris data set. The diagonal elements represent the number of points for which the predicted label is e...
scikit-learn.org
'머신러닝' 카테고리의 다른 글
| 희소행렬 (sparse matrix) (0) | 2023.03.29 |
|---|---|
| TF-IDF(Term Frequency-Inverse Document Frequency) (0) | 2023.03.28 |
| 그리드 서치 (Grid Search) (0) | 2023.03.28 |
| 교차 검증(Cross-validation) (0) | 2023.03.28 |
| T-SNE (t-distributed stochastic neighbor embedding) (0) | 2023.03.28 |