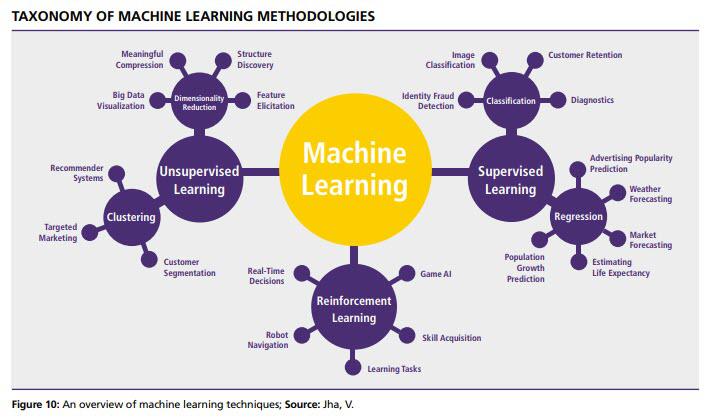
머신러닝의 흐름을 이해할 수 있도록 분류체계에 대한 이해를 돕고자 한다. 서플라이체인과 관련하여 머신러닝이 사용된다는 포브스의 기사가 있고 관련 사진을 공유한다. 시간이 되시는 분들은 출처링크에 가서 기사를 읽어보는 것을 추천한다. Forbes - 10 Ways Machine Learning Is Revolutionizing Supply Chain Management 머신러닝의 3가지 분류 지도학습(Supervised Learning) - 분류 , 회귀 정답을 알려주며 학습시키는 것을 의미한다. 환자별 질병 증상데이터에(input) 발병 미발병 등 (labelling)을 기록하여 컴퓨터에 전달한다. 컴퓨터는 학습과 검증데이터를 통해(train set, test set) 학습이 올바로 되었는지 확인할 수 ..