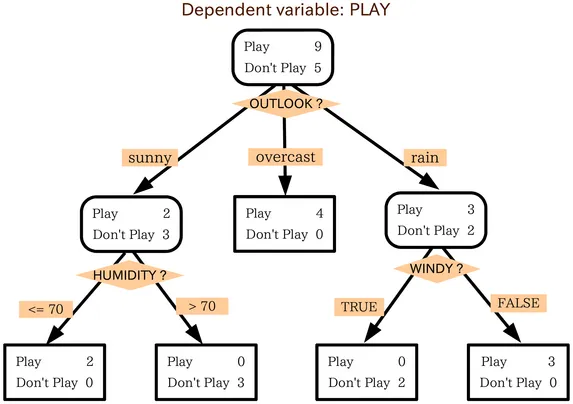
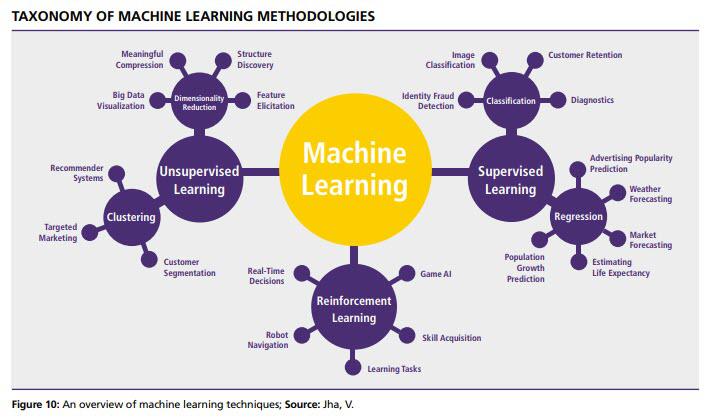
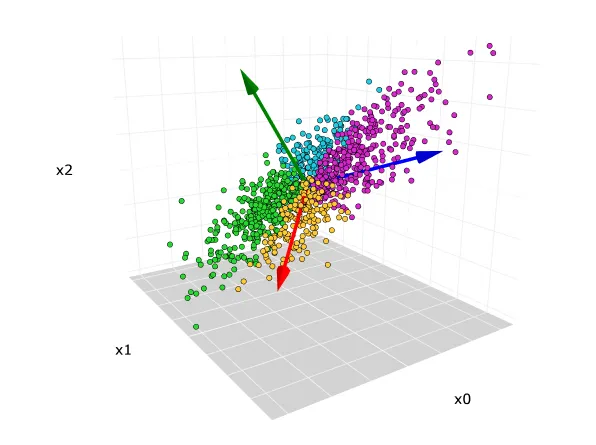
본 페이지는 "파이썬 라이브러리를 활용한 머신러닝"의 데이터와 코드 이해를 돕고자 작성한 페이지 입니다. 책을 구매해 주시면 감사하겠습니다. 머신러닝을 위한 질문 어떤 정보를 얻기 위해 질문을 하고 있나요? 그 정보는 제공 가능한 데이터로부터 추론될 수 있나요? 머신러닝의 관점에서, 내가 가진 문제를 가장 잘 기술하는 방법은 무엇일까요? 문제를 해결하는 데 필요한 데이터는 충분히 수집되었나요? 수집한 데이터의 특성은 무엇이며, 좋은 예측 결과를 만들어낼 수 있을까요? 머신러닝 모델의 성능을 어떻게 측정할 수 있나요? 머신러닝 솔루션이 다른 연구나 제품과 어떻게 상호작용할 수 있을까요? 머신러닝으로 해결할 수 있는 문제 예시: 지도 학습: 손으로 쓴 우편번호 숫자 인식 의료 영상을 기반으로 한 종양 판단 ..