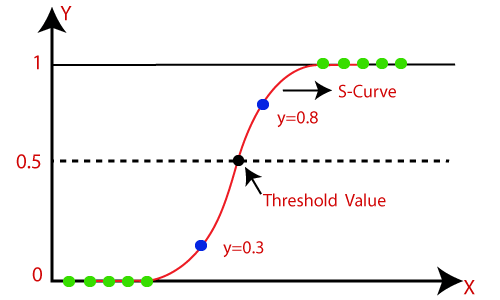
로지스틱 회귀(Logistic Regression)는 분류(Classification) 알고리즘 중 하나로, 입력 변수(x)와 이진 종속 변수(y) 사이의 관계를 찾는 모델입니다. 이진 종속 변수는 보통 0과 1로 표현되며, 로지스틱 회귀 모델은 입력 변수와 이진 종속 변수 간의 선형 관계를 모델링하기 때문에 선형 분류 문제에 많이 사용됩니다. 로지스틱 회귀 모델은 이진 분류뿐만 아니라 다중 분류(Multiclass Classification) 문제에도 적용할 수 있습니다. 다중 분류 문제에서는 소프트맥스 함수(Softmax function)를 사용하여 각 클래스에 대한 확률값을 계산하고, 가장 높은 확률값을 가진 클래스로 분류합니다. 로지스틱 회귀에서는 회귀선을 맞추는 대신 "S"자 모양의 로지스틱 함..